Friday, 14 September 2012
Creating Process Chains for DSO
A process chain is a sequence of processes that are scheduled to wait in the background for an event. Some of these processes trigger a separate event that can, in turn, start other processes. It looks similar to a flow chart. You define the list of Infopackages / DTPs that is needed to load the data, say delta or Full load. Then you schedule the Process chain as hourly, daily, monthly, etc, depending on the requirement
Use: If you want to automatically load and schedule a hierarchy, you can include this as an application process in the procedure for a Process Chain
Note: Before you define process chains, you need to have the Objects ready i.e DSO, Cubes etc
Steps to Create Process Chains
Step 1: Go to RSPC transaction. Click on Create. Give Process chain name and Description.

Step 2: Give the Start process name and description and click on Enter
Note: Each process chain should start with a Start Process

Step 3: The next screen will show the Scheduling options.
There are two options:
Direct Scheduling:
Start Using Meta Chain or API
In my example I have chosen Direct Scheduling as I am processing only one chain i.e DSO. Click on “Change Selections”

In the below screen shot, you can give the scheduling details i.e the Immediate, Date& time etc. and click on SAVE

The Screen shot below indicates that we have started the process.

Step 4:
Click on the icon process types as shown in the below figure. You will get a list of options.
In my example I am scheduling for DSO. To process we need to have InfoPackage, DTP’s for the corresponding DSO
Open the tree Load Process and Post Processing, We need to drag and drop “Execute InfoPackage”


Step 5: Once you drag and drop the “Execute infopackage” we get the below Popup. We need to keyin the Infopackage name. To do this click on F4 and chose your Infopackage and click onENTER


Step 6: Once you drag & drop the InfoPackage, the corresponding DTP’s and the corresponding Active Data table are automatically called.

Step 7: Save + Activate and Execute the Process.
Step 8: Once the process is completed, we can see the whole chain converted to Green, Which indicates the process is successfully completed
Note: In case of errors in any step, the particular chain will be displayed in red
Step 9: We can see if the data is successfully updated by Right-click on the Data store Data

Step 10: On selecting Administer Data Target, will lead you to InfoProvider Administration.


Step 11: Click on “Active Data” tab to see the data successfully uploaded.

Note:
Similarly the process can be done for Cubes, Master data and Transactional data
When you create Process chains, by default they are stored in “Not Assigned”. If you want to create your own folders,
a) Click on the icon “Display Components” on your toolbar => choose F4 => Create



b) Give appropriate name for the folder => Enter

c) SAVE + ACTIVATE
Changes in BI 7.0 and BW 3.5
Below are the major changes in BI 7.0 or 2004S version when compared with earlier versions.
- In Infosets now you can include Infocubes as well.
- The Remodeling transaction helps you add new key figure and characteristics and handles historical data as well without much hassle. This is only for info cube.
- The BI accelerator (for now only for infocubes) helps in reducing query run time by almost a factor of 10 - 100. This BI accl is a separate box and would cost more. Vendors for these would be HP or IBM.
- The monitoring has been improved with a new portal based cockpit. Which means you would need to have an EP guy in ur project for implementing the portal !
- Search functionality has improved!! You can search any object. Not like 3.
- Transformations are in and routines are passe! Yes, you can always revert to the old transactions too
- Renamed ODS as DataStore.
- Inclusion of Write-optimized DataStore which does not have any change log and the requests do need any activation
- Unification of Transfer and Update rules
- Introduction of "end routine" and "Expert Routine"
- Push of XML data into BI system (into PSA) without Service API or Delta Queue
- Introduction of BI accelerator that significantly improves the performance.
- Load through PSA has become a must. It looks like we would not have the option to bypass the PSA during data load.
Metadata Search (Developer Functionality) :
- It is possible to search BI metadata (such as InfoCubes, InfoObjects, queries, Web templates) using the TREX search engine. This search is integrated into the Metadata Repository, the Data Warehousing Workbench and to some degree into the object editors. With the simple search, a search for one or all object types is performed in technical names and in text.
- During the text search, lower and uppercase are ignored and the object will also be found when the case in the text is different from that in the search term. With the advanced search, you can also search in attributes. These attributes are specific to every object type. Beyond that, it can be restricted for all object types according to the person who last changed it and according to the time of the change.
- For example, you can search in all queries that were changed in the last month and that include both the term "overview" in the text and the characteristic customer in the definition. Further functions include searching in the delivered (A) version, fuzzy search and the option of linking search terms with "AND" and "OR".
- "Because the advanced search described above offers more extensive options for search in metadata, the function ""Generation of Documents for Metadata"" in the administration of document management (transaction RSODADMIN) was deleted. You have to schedule (delta) indexing of metadata as a regular job (transaction RSODADMIN).
Effects on Customizing
Installation of TREX search engine
Creation of an RFC destination for the TREX search engine
Entering the RFC destination into table RSODADMIN_INT
Determining relevant object types
Initial indexing of metadata
Remote Activation of DataSources (Developer Functionality) :
1. When activating Business Content in BI, you can activate DataSources remotely from the BI system. This activation is subject to an authorization check. You need role SAP_RO_BCTRA. Authorization object S_RO_BCTRA is checked. The authorization is valid for all DataSources of a source system. When the objects are collected, the system checks the authorizations remotely, and issues a warning if you lack authorization to activate the DataSources.
2. In BI, if you trigger the transfer of the Business Content in the active version, the results of the authorization check are based on the cache. If you lack the necessary authorization for activation, the system issues a warning for the DataSources. BW issues an error for the corresponding source-system-dependent objects (transformations, transfer rules, transfer structure, InfoPackage, process chain, process variant). In this case, you can use Customizing for the extractors to manually transfer the required DataSources in the source system from the Business Content, replicate them in the BI system, and then transfer the corresponding source-system-dependent objects from the Business Content. If you have the necessary authorizations for activation, the DataSources in the source system are transferred to the active version and replicated in the BI system. The source-system-dependent objects are activated in the BI system.
3. Source systems and/or BI systems have to have BI Service API SAP NetWeaver 2004s at least; otherwise remote activation is not supported. In this case, you have to activate the DataSources in the source system manually and then replicate them to the BI system.
Copy Process Chains (Developer Functionality):
You find this function in the Process Chain menu and use it to copy the process chain you have selected, along with its references to process variants, and save it under a new name and description.
InfoObjects in Hierarchies (Data Modeling):
1. Up to Release SAP NetWeaver 2004s, it was not possible to use InfoObjects with a length longer than 32 characters in hierarchies. These types of InfoObjects could not be used as a hierarchy basic characteristic and it was not possible to copy characteristic values for such InfoObjects as foreign characteristic nodes into existing hierarchies. From SAP NetWeaver 2004s, characteristics of any length can be used for hierarchies.
2. To load hierarchies, the PSA transfer method has to be selected (which is always recommended for loading data anyway). With the IDOC transfer method, it continues to be the case that only hierarchies can be loaded that contain characteristic values with a length of less than or equal to 32 characters.
Parallelized Deletion of Requests in DataStore Objects (Data Management) :
Now you can delete active requests in a DataStore object in parallel. Up to now, the requests were deleted serially within an LUW. This can now be processed by package and in parallel.
Object-Specific Setting of the Runtime Parameters of DataStore Objects (Data Management):
Now you can set the runtime parameters of DataStore objects by object and then transport them into connected systems. The following parameters can be maintained:
- Package size for activation
- Package size for SID determination
- Maximum wait time before a process is designated lost
- Type of processing: Serial, Parallel(batch), Parallel (dialog)
- Number of processes to be used
- Server/server group to be used
Enhanced Monitor for Request Processing in DataStore Objects (Data Management):
1. for the request operations executed on DataStore objects (activation, rollback and so on), there is now a separate, detailed monitor. In previous releases, request-changing operations are displayed in the extraction monitor. When the same operations are executed multiple times, it will be very difficult to assign the messages to the respective operations.
2. In order to guarantee a more simple error analysis and optimization potential during configuration of runtime parameters, as of release SAP NetWeaver 2004s, all messages relevant for DataStore objects are displayed in their own monitor.
Write-Optimized DataStore Object (Data Management):
1. Up to now it was necessary to activate the data loaded into a DataStore object to make it visible to reporting or to be able to update it to further InfoProviders. As of SAP NetWeaver 2004s, a new type of DataStore object is introduced: the write-optimized DataStore object.
2. The objective of the new object type is to save data as efficiently as possible in order to be able to further process it as quickly as possible without addition effort for generating SIDs, aggregation and data-record based delta. Data that is loaded into write-optimized DataStore objects is available immediately for further processing. The activation step that has been necessary up to now is no longer required.
3. The loaded data is not aggregated. If two data records with the same logical key are extracted from the source, both records are saved in the DataStore object. During loading, for reasons of efficiency, no SID values can be determined for the loaded characteristics. The data is still available for reporting. However, in comparison to standard DataStore objects, you can expect to lose performance because the necessary SID values have to be determined during query runtime.
Deleting from the Change Log (Data Management):
The Deletion of Requests from the Change Log process type supports the deletion of change log files. You select DataStore objects to determine the selection of requests. The system supports multiple selections. You select objects in a dialog box for this purpose. The process type supports the deletion of requests from any number of change logs.
Using InfoCubes in InfoSets (Data Modeling):
1. You can now include InfoCubes in an InfoSet and use them in a join. InfoCubes are handled logically in InfoSets like DataStore objects. This is also true for time dependencies. In an InfoCube, data that is valid for different dates can be read.
2. For performance reasons you cannot define an InfoCube as the right operand of a left outer join. SAP does not generally support more than two InfoCubes in an InfoSet.
Pseudo Time Dependency of DataStore Objects and InfoCubes in InfoSets (Data Modeling) :
In BI only master data can be defined as a time-dependent data source. Two additional fields/attributes are added to the characteristic. DataStore objects and InfoCubes that are being used as InfoProviders in the InfoSet cannot be defined as time dependent. As of SAP NetWeaver 2004s, you can specify a date or use a time characteristic with DataStore objects and InfoCubes to describe the validity of a record. These InfoProviders are then interpreted as time-dependent data sources.
Left Outer: Include Filter Value in On-Condition (Data Modeling) :
The global properties in InfoSet maintenance have been enhanced by one setting Left Outer: Include Filter Value in On-Condition. This indicator is used to control how a condition on a field of a left-outer table is converted in the SQL statement. This affects the query results:
- If the indicator is set, the condition/restriction is included in the on-condition in the SQL statement. In this case the condition is evaluated before the join.
- If the indicator is not set, the condition/restriction is included in the where-condition. In this case the condition is only evaluated after the join.
- The indicator is not set by default.
Key Date Derivation from Time Characteristics (Data Modeling) :
Key dates can be derived from the time characteristics 0CALWEEK, 0CALMONTH, 0CALQUARTER, 0CALYEAR, 0FISCPER, 0FISCYEAR: It was previously possible to specify the first, last or a fixed offset for key date derivation. As of SAP NetWeaver 2004s, you can also use a key date derivation type to define the key date.
Repartitioning of InfoCubes and DataStore Objects (Data Management):
With SAP NetWeaver 2004s, the repartitioning of InfoCubes and DataStore objects on the database that are already filled is supported. With partitioning, the runtime for reading and modifying access to InfoCubes and DataStore objects can be decreased. Using repartitioning, non-partitioned InfoCubes and DataStore objects can be partitioned or the partitioning schema for already partitioned InfoCubes and DataStore objects can be adapted.
Remodeling InfoProviders (Data Modeling):
1. As of SAP NetWeaver 2004s, you can change the structure of InfoCubes into which you have already loaded data, without losing the data. You have the following remodeling options:
2. For characteristics:
- Inserting, or replacing characteristics with: Constants, Attribute of an InfoObject within the same dimension, Value of another InfoObject within the same dimension, Customer exit (for user-specific coding).
- Delete
3. For key figures:
- Inserting: Constants, Customer exit (for user-specific coding).
- Replacing key figures with: Customer exit (for user-specific coding).
- Delete
4. SAP NetWeaver 2004s does not support the remodeling of InfoObjects or DataStore objects. This is planned for future releases. Before you start remodeling, make sure:
(A) You have stopped any process chains that run periodically and affect the corresponding InfoProvider. Do not restart these process chains until remodeling is finished.
(B) There is enough available tablespace on the database.
After remodeling, check which BI objects that are connected to the InfoProvider (transformation rules, MultiProviders, queries and so on) have been deactivated. You have to reactivate these objects manually
Parallel Processing for Aggregates (Performance):
1. The change run, rollup, condensing and checking up multiple aggregates can be executed in parallel. Parallelization takes place using the aggregates. The parallel processes are continually executed in the background, even when the main process is executed in the dialog.
2. This can considerably decrease execution time for these processes. You can determine the degree of parallelization and determine the server on which the processes are to run and with which priority.
3. If no setting is made, a maximum of three processes are executed in parallel. This setting can be adjusted for a single process (change run, rollup, condensing of aggregates and checks). Together with process chains, the affected setting can be overridden for every one of the processes listed above. Parallelization of the change run according to SAP Note 534630 is obsolete and is no longer being supported.
Multiple Change Runs (Performance):
1. You can start multiple change runs simultaneously. The prerequisite for this is that the lists of the master data and hierarchies to be activated are different and that the changes affect different InfoCubes. After a change run, all affected aggregates are condensed automatically.
2. If a change run terminates, the same change run must be started again. You have to start the change run with the same parameterization (same list of characteristics and hierarchies). SAP Note 583202 is obsolete.
Partitioning Optional for Aggregates (Performance):
1. Up to now, the aggregate fact tables were partitioned if the associated InfoCube was partitioned and the partitioning characteristic was in the aggregate. Now it is possible to suppress partitioning for individual aggregates. If aggregates do not contain much data, very small partitions can result. This affects read performance. Aggregates with very little data should not be partitioned.
2. Aggregates that are not to be partitioned have to be activated and filled again after the associated property has been set.
MOLAP Store (Deleted) (Performance):
Previously you were able to create aggregates either on the basis of a ROLAP store or on the basis of a MOLAP store. The MOLAP store was a platform-specific means of optimizing query performance. It used Microsoft Analysis Services and, for this reason, it was only available for a Microsoft SQL server database platform. Because HPA indexes, available with SAP NetWeaver 2004s, are a platform-independent alternative to ROLAP aggregates with high performance and low administrative costs, the MOLAP store is no longer being supported.
Data Transformation (Data Management):
1. A transformation has a graphic user interfaces and replaces the transfer rules and update rules with the functionality of the data transfer process (DTP). Transformations are generally used to transform an input format into an output format. A transformation consists of rules. A rule defines how the data content of a target field is determined. Various types of rule are available to the user such as direct transfer, currency translation, unit of measure conversion, routine, read from master data.
2. Block transformations can be realized using different data package-based rule types such as start routine, for example. If the output format has key fields, the defined aggregation behavior is taken into account when the transformation is performed in the output format. Using a transformation, every (data) source can be converted into the format of the target by using an individual transformation (one-step procedure). An InfoSource is only required for complex transformations (multistep procedures) that cannot be performed in a one-step procedure.
3. The following functional limitations currently apply:
- You cannot- use hierarchies as the source or target of a transformation.
- You can- not use master data as the source of a transformation.
- You cannot- use a template to create a transformation.
- No- documentation has been created in the metadata repository yet for transformations.
- In the- transformation there is no check for referential integrity, the InfoObject transfer routines are not considered and routines cannot be created using the return table.
Quantity Conversion :
As of SAP NetWeaver 2004s you can create quantity conversion types using transaction RSUOM. The business transaction rules of the conversion are established in the quantity conversion type. The conversion type is a combination of different parameters (conversion factors, source and target units of measure) that determine how the conversion is performed. In terms of functionality, quantity conversion is structured similarly to currency translation. Quantity conversion allows you to convert key figures with units that have different units of measure in the source system into a uniform unit of measure in the BI system when you update them into InfoCubes.
Data Transfer Process :
You use the data transfer process (DTP) to transfer data within BI from a persistent object to another object in accordance with certain transformations and filters. In this respect, it replaces the InfoPackage, which only loads data to the entry layer of BI (PSA), and the data mart interface. The data transfer process makes the transfer processes in the data warehousing layer more transparent. Optimized parallel processing improves the performance of the transfer process (the data transfer process determines the processing mode). You can use the data transfer process to separate delta processes for different targets and you can use filter options between the persistent objects on various levels. For example, you can use filters between a DataStore object and an InfoCube. Data transfer processes are used for standard data transfer, for real-time data acquisition, and for accessing data directly. The data transfer process is available as a process type in process chain maintenance and is to be used in process chains.
ETL Error Handling :
The data transfer process supports you in handling data records with errors. The data transfer process also supports error handling for DataStore objects. As was previously the case with InfoPackages, you can determine how the system responds if errors occur. At runtime, the incorrect data records are sorted and can be written to an error stack (request-based database table). After the error has been resolved, you can further update data to the target from the error stack. It is easier to restart failed load processes if the data is written to a temporary store after each processing step. This allows you to determine the processing step in which the error occurred. You can display the data records in the error stack from the monitor for the data transfer process request or in the temporary storage for the processing step (if filled). In data transfer process maintenance, you determine the processing steps that you want to store temporarily.
InfoPackages :
InfoPackages only load the data into the input layer of BI, the Persistent Staging Area (PSA). Further distribution of the data within BI is done by the data transfer processes. The following changes have occurred due to this:
- New tab page: Extraction -- The Extraction tab page includes the settings for adaptor and data format that were made for the DataSource. If data transfer from files occurred, the External Data tab page is obsolete; the settings are made in DataSource maintenance.
- Tab page: Processing -- Information on how the data is updated is obsolete because further processing of the data is always controlled by data transfer processes.
- Tab page: Updating -- On the Updating tab page, you can set the update mode to the PSA depending on the settings in the DataSource. In the data transfer process, you now determine how the update from the PSA to other targets is performed. Here you have the option to separate delta transfer for various targets.
For real-time acquisition with the Service API, you create special InfoPackages in which you determine how the requests are handled by the daemon (for example, after which time interval a request for real-time data acquisition should be closed and a new one opened). For real-time data acquisition with Web services (push), you also create special InfoPackages to set certain parameters for real-time data acquisition such as sizes and time limits for requests.
PSA :
The persistent staging area (PSA), the entry layer for data in BI, has been changed in SAP NetWeaver 2004s. Previously, the PSA table was part of the transfer structure. You managed the PSA table in the Administrator Workbench in its own object tree. Now you manage the PSA table for the entry layer from the DataSource. The PSA table for the entry layer is generated when you activate the DataSource. In an object tree in the Data Warehousing Workbench, you choose the context menu option Manage to display a DataSource in PSA table management. You can display or delete data here. Alternatively, you can access PSA maintenance from the load process monitor. Therefore, the PSA tree is obsolete.
Real-Time Data Acquisition :
Real-time data acquisition supports tactical decision making. You use real-time data acquisition if you want to transfer data to BI at frequent intervals (every hour or minute) and access this data in reporting frequently or regularly (several times a day, at least). In terms of data acquisition, it supports operational reporting by allowing you to send data to the delta queue or PSA table in real time. You use a daemon to transfer DataStore objects that have been released for reporting to the ODS layer at frequent regular intervals. The data is stored persistently in BI. You can use real-time data acquisition for DataSources in SAP source systems that have been released for real time, and for data that is transferred into BI using the Web service (push). A daemon controls the transfer of data into the PSA table and its further posting into the DataStore object. In BI, InfoPackages are created for real-time data acquisition. These are scheduled using an assigned daemon and are executed at regular intervals. With certain data transfer processes for real-time data acquisition, the daemon takes on the further posting of data to DataStore objects from the PSA. As soon as data is successfully posted to the DataStore object, it is available for reporting. Refresh the query display in order to display the up-to-date data. In the query, a time stamp shows the age of the data. The monitor for real-time data acquisition displays the available daemons and their status. Under the relevant DataSource, the system displays the InfoPackages and data transfer processes with requests that are assigned to each daemon. You can use the monitor to execute various functions for the daemon, DataSource, InfoPackage, data transfer process, and requests.
Archiving Request Administration Data :
You can now archive log and administration data requests. This allows you to improve the performance of the load monitor and the monitor for load processes. It also allows you to free up tablespace on the database. The archiving concept for request administration data is based on the SAP NetWeaver data archiving concept. The archiving object BWREQARCH contains information about which database tables are used for archiving, and which programs you can run (write program, delete program, reload program). You execute these programs in transaction SARA (archive administration for an archiving object). In addition, in the Administration functional area of the Data Warehousing Workbench, in the archive management for requests, you can manage archive runs for requests. You can execute various functions for the archive runs here.
After an upgrade, use BI background management or transaction SE38 to execute report RSSTATMAN_CHECK_CONVERT_DTA and report RSSTATMAN_CHECK_CONVERT_PSA for all objects (InfoProviders and PSA tables). Execute these reports at least once so that the available request information for the existing objects is written to the new table for quick access, and is prepared for archiving. Check that the reports have successfully converted your BI objects. Only perform archiving runs for request administration data after you have executed the reports.
Flexible process path based on multi-value decisions :
The workflow and decision process types support the event Process ends with complex status. When you use this process type, you can control the process chain process on the basis of multi-value decisions. The process does not have to end simply successfully or with errors; for example, the week day can be used to decide that the process was successful and determine how the process chain is processed further. With the workflow option, the user can make this decision. With the decision process type, the final status of the process, and therefore the decision, is determined on the basis of conditions. These conditions are stored as formulas.
Evaluating the output of system commands :
You use this function to decide whether the system command process is successful or has errors. You can do this if the output of the command includes a character string that you defined. This allows you to check, for example, whether a particular file exists in a directory before you load data to it. If the file is not in the directory, the load process can be repeated at pre-determined intervals.
Repairing and repeating process chains :
You use this function to repair processes that were terminated. You execute the same instance again, or repeat it (execute a new instance of the process), if this is supported by the process type. You call this function in log view in the context menu of the process that has errors. You can restart a terminated process in the log view of process chain maintenance when this is possible for the process type.
If the process cannot be repaired or repeated after termination, the corresponding entry is missing from the context menu in the log view of process chain maintenance. In this case, you are able to start the subsequent processes. A corresponding entry can be found in the context menu for these subsequent processes.
Executing process chains synchronously :
You use this function to schedule and execute the process in the dialog, instead of in the background. The processes in the chain are processed serially using a dialog process. With synchronous execution, you can debug process chains or simulate a process chain run.
Error handling in process chains:
You use this function in the attribute maintenance of a process chain to classify all the incorrect processes of the chain as successful, with regard to the overall status of the run, if you have scheduled a successor process Upon Errors or Always. This function is relevant if you are using metachains. It allows you to continue processing metachains despite errors in the subchains, if the successor of the subchain is scheduled Upon Success.
Determining the user that executes the process chain :
You use this function in the attribute maintenance of a process chain to determine which user executes the process chain. In the default setting, this is the BI background user.
Display mode in process chain maintenance :
When you access process chain maintenance, the process chain display appears. The process chain is not locked and does not call the transport connection. In the process chain display, you can schedule without locking the process chain.
Checking the number of background processes available for a process chain :
During the check, the system calculates the number of parallel processes according to the structure of the tree. It compares the result with the number of background processes on the selected server (or the total number of all available servers if no server is specified in the attributes of the process chain). If the number of parallel processes is greater than the number of available background processes, the system highlights every level of the process chain where the number of processes is too high, and produces a warning.
Open Hub / Data Transfer Process Integration :
As of SAP NetWeaver 2004s SPS 6, the open hub destination has its own maintenance interface and can be connected to the data transfer process as an independent object. As a result, all data transfer process services for the open hub destination can be used. You can now select an open hub destination as a target in a data transfer process. In this way, the data is transformed as with all other BI objects. In addition to the InfoCube, InfoObject and DataStore object, you can also use the DataSource and InfoSource as a template for the field definitions of the open hub destination. The open hub destination now has its own tree in the Data Warehousing Workbench under Modeling. This tree is structured by InfoAreas.
The open hub service with the InfoSpoke that was provided until now can still be used. We recommend, however, that new objects are defined with the new technology.
Easy way to remember all the main SAP tables used for any development
This will serve as an easy way to remember all the main SAP tables used for any development.
Remember Bank tables start with B, say "BKNF , BKPF".
Remember Customer tables start with K , say "KNA1,KONV".
Remember Material tables start with M, say "MARA , MAKT , MARC".
Remember Master data tables start with T, say "T001, T001W".
Remember Purchasing tables start with E, say "EKKO, EKPO"
Remember Sales table start with V, say "VBAK,VBAP".
Remember Vendor tables start with L, say "LFA1".
Six important FI tables.
They contain an I if it is an open item.
They contain an A if it is a closed item.
They contain an S if a GL account say "BSIS , BSAS".
Important table names of Billing, Delivery, Sales and Purchasing.
Each table had a K if it is a header data, say "VBAK, VBAP, LIKP, VBRK, EKKO".
Each table had a P if it is an item data, say "VBAP, LIPS , VBRP , EKPO".
With a D at the end , the table is a Customer
With a K at the end, the table is a Vendor.
Delta Errors
Error 1: Delta invalidation (Data mart scenario):
To solve the problem you need to reinitialize the load again (SAP recommends)
1) Delete the requests from cube which had as source the ODS. (Otherwise you will get duplicate data.)
2) Delete the initialization in the info package for the ODS-info source
3) Schedule a new init from ODS to info cube.
Workaround ( Customer's responsibility; SAP wont support incase of issues in this procedure).
You should ensure:
- The requests that really have not been loaded to the target cube are still available in the PSA for the loads to the ODS and
- You are deleting only the requests which are not loaded already.
Solution:
1. Delete ONLY the request from the source ODS which have NOT been loaded to the target cube already. If the requests which you need to delete are available in the PSA for the load to DSO then these can be reloaded to the target in a later step (see below step 4). If all requests are already loaded to the target and none are missing then you don't need to do anything in this step, proceed
2. You now need to delete the existing init request for the data mart load. To do this in the Info Package (just take one if there're several) reset the delta management in menu 'Scheduler', 'Init options for source system'.
3. Now execute an init load without data transfer, in the Info Package set the extraction mode to "Initialize without Data Transfer" and schedule the info package. This will fill RSDMDELTA with ALL requests contained in the source ODS's change log at that time. In other words this process resets the DataMart flag in the source ODS for the requests that have already been loaded.
4. Now in this step reload the requests from the PSA to the source ODS that you deleted in step 1 (if you deleted any requests).
5. The next DataMart delta from the source ODS should load these requests into the targets.
Error 2: Duplicate data in case of repeat delta:
If a delta load fails, it does NOT mean, that a repeat delta has to be executed automatically! It is necessary to analyse, if the data has already extracted correctly, and the corresponding tables (ROOSPRMSC) updated or not, before you execute a repeat delta.
Error 3: DataMart repeat request returns 0 records
After an incorrect delta, repeat delta does not fetch delta record. Reset the Data Mart status of the source request corresponding to the deleted Data Mart request in the administration view of the sourceobject.
Error 4: There are already full uploads in the ODS object and therefore inits or deltas cannot be posted or activated.
You have already loaded full requests in to the ODS. Due to business requirement, you want to change this to delta. If a full upload occurs once for an ODS object, you can no longer activate an init for the same Data Source/source system combination in this ODS object. The system does not check for overlapping selection conditions. Please execute report RSSM_SET_REPAIR_FULL_FLAG which will convert all Full loads in to repair full request.
Error 5: Unable to do compression though the delta seems to be updated in data target
When a Delta-DTP is started, pointer DMEXIST is increased to prevent the deletion of the source-request. As long as there is still a Delta-DTP or Export-Data Source that has NOT yet picked up the request, DMALL is not updated and the request cannot be compressed. When ALL Delta-DTPs AND Export-Data Sources have picked up the source-request, the pointer DMALL is increased.
So, if you are unable to do compression due to delta errors, please check that all downstream targets delta is successful. Even if one downstream target is not filled with delta data, compression is not allowed.
For Info Cubes, the contents of the RSMDATASTATE-DMEXIST and RSMDATASTATE-DMALL fields must always be equal to the largest request in the RSDMDELTA table of the relevant cube (ICNAME field).
Then only compression is possible.
In General,in table RSMDATASTATE:
DMALL <= DMEXIST <= QUALOK.
Tables to be checked in case of 3.x Flow: RSDMDELTA/RSDMSTAT
Tables to be checked in case of 7. X dataflow: RSBKREQUEST and RSSTATMANREQMAP.
For ODS objects, the contents of RSBODSLOGSTATE-PROCESSED_ALL and RSBODSLOGSTATE-PROCESSED_ONE fields must always be equal to the largest request in the RSDMDELTA table. In General,in table RSBODSLOGSTATE:
PROCESSEDALL<= PROCESSEDONE <= ACTIVE.
Error 6: Last delta incorrect. A repeat must be requested. This is not possible.
For few 0FI* extractors if the delta has failed and if You want to repeat delta which is not possible. In the standard system, you can repeat the delta extractions for the last sixty days. The number of days is defined by the 'DELTIMEST' parameter in the BWOM_SETTINGS table. Still, if you want to do repeat delta you need to change the time stamp. Please refer note 860500 for more details.
Error 7: Even after init simulation further deltas has not fetched relevant data
After initialization without data transfer delta has not fetched data. You can check if the data source is designed to perform Init simulations by checking the field ROOSOURCE-INITSIMU for the respective data source. If it's not enabled, if there is delta invalidation, only option is to do the reinit with data transfer.
Error 8: Missing delta records - in generic delta with calendar day.
Using "Calendar day" as delta-relevant field has certain disadvantages compared to the use of time stamps. If there is an adequate time stamp field in the source structure, use this field as delta-relevant field.
Error 9: Dump while execution of delta info package / opening an info package.
"MESSAGE_TYPE_X" "SAPLRSSM" or "LRSSMU36" "RSSM_OLTPSOURCE_SELECTIONS"
Reasons: Improper system copy / Terminated initialization / Overlapping initialization selection.
This dump happens due to inconsistent entries in table RSSDLINIT: (BW system) & ROOSPRMSC, ROOSPRMSF (OLTP system).
Error 10: Delta is lost after a system copy:
You have copied a source system and BW system is not copied. For delta to work from new copied source system, Repair the delta queue In the BW system: Execute report RSSM_OLTP_INIT_DELTA_UPDATE for each data source, which has an active init request. Provide the field 'ALWAYS' with value 'X'. This will push the init / delta information of the BW into the source system, thus allows to continue loading delta or to do a new init.
This report will update the delta tables in the source and from technical point of few delta upload will be possible, but you should be aware that in case of system copy (if you copy only one system not both) you cannot compare the data between source and BW system, a new init is suggested.
Error 11: How to load delta from failed delta request:
Delta is having missing records. It's not the latest delta as we don't know when the problem has occurred.
Error 12: CO-PA Data source: No new data since last delta update (Though the delta data exists!)
First delta has failed. And the repeat delta has fetched 0 records, though there are records in source. It is just normal that the first delta after a failed one finishes successful, but extracted zero records. The reason is that this is a repeat from the delta queue and as the delta run before did not extract anything due to the status of the data source in KEB2 the delta queue was empty and so the repeat just extracts the empty delta queue. After such a successful repeat you should just execute another delta run that should extract the desired data.
Error 13: Write optimized DSO has not fetched Delta
You need to run the report RSSM_WO_DSO_REPAIR_RSBODSLOG, which generates these missing entries.
Questions:
1. What are the possible reasons for delta invalidation?
There can be multiple reasons with which delta management can be invalidated like if
1) Info Cube: a request is compressed which has not been delta-updated to all downstream targets.
2) Request is deleted, which already had been delta-updated to one or more downstream targets.
How to find the delta invalidation:
To check if the delta management is invalidated, look up table RSDMSTAT-DMDELTAINA. The field DMDELTAINA (delta status) should be set to X. Also the table RSDMDELTA will not contain any data for this source/target combination.
2. Is it good to go for repair full request / reinit incase of missing delta:
It depends on parameters like: Volume of missing delta, possibility for selective deletion and the type of Downstream Data target.
Note that you should only use repair full request if you have a small number of incorrect or missing records. Otherwise, SAP always recommends a re-initialization (possibly after a previous selective deletion, followed by a restriction of the Delta-Init selection to exclude areas that were not changed in the meantime).
Please follow note 739863 for further details.
3. Is it possible to do initalization with out data transfer in DTP?
Unlike delta transfer using an InfoPackage, an explicit initialization of the delta process is not necessary for delta transfer with a DTP. When the data transfer process is executed in delta mode for the first time, all existing requests are retrieved from the source and the delta status is initialized. This implies that to re-init all existing requests must be deleted.
If you want to execute a delta without transferring data, analogous to the simulation of the delta initialization with the InfoPackage, select No data transfer; delta status in source: fetched as processing mode. This processing mode is available when the data transfer process extracts in delta mode. A request started like this marks the data that is found in the source as fetched, without actually transferring it to the target.
If you dont need delta DTP anymore, you can execute report: RSBK_LOGICAL_DELETE_DTP for the delta DTP that you want to be deactivated. Afterwards, the delta DTP will no longer be able to be executed and requests that have already been transferred will no longer be taken into account in the calculation of the data mart water level.
For the data mart, the system behaves as if the delta DTP never existed.
Please refer note 1450242 for further details.
4. Important tables in Delta / Data mart Scenarios:
RSSDLINIT: (BW system): Last Valid Initializations to an OLTP Source
ROOSPRMSC (OLTP system): Control Parameter Per DataSource Channel
ROOSPRMSF : Control Parameters Per DataSource
RSSDLINITSEL: Last Valid Initializations to an OLTP Source
RSDMDELTA: Data Mart Delta Management
This table contains the list of all the requests which are already fetched by the target system.
ROOSGENDLM: Generic Delta Management for DataSources (Client-Dep.)
RSBKREQUEST: DTP Request
RSSTATMANREQMAP: Mapping of Higher- to Lower-Level Status Manager Request
RSDMSTAT: Data mart Status Table
This table is used for processing a Repeat Delta. Using field DMCOUNTER we can follow up in RSDMDELTA.
RSMDATASTATE: Status of the data in the Infocubes
This table is used to know the state of the Data Target regarding compression, aggregation etc. For Data Marts the two field DMEXIST and DMALL are used.
RODELTAM: BW Delta Process
ROOSGEN: Generated Objects for OLTP Source
RSSELDONE: Monitor: Selections for executed request
RSSTATMANPART: Store for G_T_PART of Request Display in DTA Administration
RSBODSLOGSTATE: Change log Status for ODS Object
ROOSOURCE: Table Header for SAP BW OLTP Sources
Mainly used to get data regarding Initialization of the Extractor. It contains the header metadata of Datasources, e.g. if the datasource is capable of delta extraction.
5. Important corrections in BC-BW area:
1460643 Performance problems with asynchronous RFC
1250813 SAPLARFC uses all dialog work processes
1377863 Max no of gateways exceeded
1280898 IDoc hangs when it is to be sent immediately with
1055679 IDoc-tRFC inbound with immediate processing may not
1051445 qRFC scheduler does not use all available resourcen
1032638 Myself extraction: Cursor disappears, IDocs in
995057 Multiple execution of tRFC
977283 Outbound scheduler remains in WAITING status for a long time
Wednesday, 12 September 2012
Time stamp error
Reason
The “Time Stamp” Error occurs when the Transfer Rules or Transfer Structure are internally inactive in the system.
They can also occur whenever the Data Sources are changed on the R/3 side or the DataMarts are changed in BW side. In that case, the Transfer Rules is showing active status when checked. But they are actually not, it happens because the time stamp between the Data Source and theTransfer Rules are different.

Solution
1. Go to RSA1 --> Source system --> Replicate DataSource

2. Run the program RS_TRANSTRU_ACTIVATE_ALL

3. Mention Source System and Info Source and then execute.

Now the Transfer Structure will be automatically activated then proceed with the reload, it will get success now.
LO COCKPIT
Logistic Cockpit (LC) is the technique to extract logistics transaction data from R/3.
All the Data Sources belonging to logistics can be found in the LO Cockpit (Transaction LBWE) grouped by their respective application areas.

The Data Sources for logistics are delivered by SAP as a part of its standard business content in the SAP ECC 6.0 system and has the following naming convention. A logistics transaction DataSource is named as follows: 2LIS_<Application>_<Event><Suffix> where,
- Every LO Data Source starts with 2LIS.
- Application is specified by a two digit number that specifies the application relating to a set of events in a process. e.g. application 11 refers to SD sales.
- Event specifies the transaction that provides the data for the application specified, and is optional in the naming convention. e.g. event VA refers to creating, changing or deleting sales orders. (Verkauf Auftrag stands for sales order in German).
- Suffix specifies the details of information that is extracted. For e.g. ITM refers to item data, HDR refers to header data, and SCL refers to schedule lines.
Up on activation of the business content Data Sources, all components like the extract structure, extractor program etc. also gets activated in the system.
The extract structure can be customized to meet specific reporting requirements at a later point of time and necessary user exits can also be made use of for achieving the same.
An extract structure generated will have the naming convention, MC <Application> <Event>0 <Suffix>. Where, suffix is optional. Thus e.g. 2LIS_11_VAITM, sales order item, will have the extract structure MC11VA0ITM.
Delta Initialization:
- LO Data Sources use the concept of setup tables to carry out the initial data extraction process.
- The presence of restructuring/setup tables prevents the BI extractors directly access the frequently updated large logistics application tables and are only used for initialization of data to BI.
- For loading data first time into the BI system, the setup tables have to be filled.
Delta Extraction:
- Once the initialization of the logistics transaction data Data Source is successfully carried out, all subsequent new and changed records are extracted to the BI system using the delta mechanism supported by the Data Source.
- The LO Data Sources support ABR delta mechanism which is both DSO and InfoCube compatible. The ABR delta creates delta with after, before and reverse images that are updated directly to the delta queue, which gets automatically generated after successful delta initialization.
- The after image provides status after change, a before image gives status before the change with a minus sign and a reverse image sends the record with a minus sign for the deleted records.
- The type of delta provided by the LO Data Sources is a push delta, i.e. the delta data records from the respective application are pushed to the delta queue before they are extracted to BI as part of the delta update. The fact whether a delta is generated for a document change is determined by the LO application. It is a very important aspect for the logistic Data Sources as the very programthat updates the application tables for a transaction triggers/pushes the data for information systems, by means of an update type, which can be a V1 or a V2 update.
- The delta queue for an LO Data Source is automatically generated after successful initialization and can be viewed in transaction RSA7, or in transaction SMQ1 under name MCEX<Application>.
Update Method
The following three update methods are available
Synchronous update (V1 update)
Asynchronous update (V2 update)
Collective update (V3 update)
Synchronous update (V1 update)
Statistics updates is carried out oat the same time as the document update in the application table, means whenever we create a transaction in R/3, then the entries get into the R/3 table and this takes place in v1 update.
Asynchronous update (V2 update)
Document update and the statistics update take place in different tasks. V2 update starts a few seconds after V1 update and this update the values get into statistical tables from where we do the extraction into BW.
V1 and V2 updates do not require any scheduling activity.
Collective update (V3 update)
V3 update uses delta queue technology is similar to the V2 update. The main differences is that V2 updates are always triggered by applications while V3 update may be scheduled independently.
Update modes
Direct Delta
Queued Delta
Unserialized V3 Update

Direct Delta
- With this update mode, extraction data is transferred directly to the BW delta queues with each document posting.
- Each document posted with delta extraction is converted to exactly one LUW in the related BW delta queues.
- In this update mode no need to schedule a job at regular intervals (through LBWE “Job control”) in order to transfer the data to the BW delta queues. Thus additional monitoring of update data or extraction queue is not require.
- This update method is recommended only for customers with a low occurrence of documents (a maximum of 10000 document changes - creating, changing or deleting - between two delta extractions) for the relevant application.
Queued Delta
- With queued delta update mode, the extraction data is written in an extraction queue and then that data can be transferred to the BW delta queues by extraction collective run.
- If we use this method, it will be necessary to schedule a job to regularly transfer the data to the BW delta queues i.e extraction collective run.
- SAP recommends to schedule this job hourly during normal operation after successful delta initialization, but there is no fixed rule: it depends from peculiarity of every specific situation (business volume, reporting needs and so on).
Unserialized V3 Update
- With this Unserialized V3 Update, the extraction data is written in an update table and then that data can be transferred to the BW delta queues by V3 collective run.
Setup Table
- Setup table is a cluster table that is used to extract data from R/3 tables of same application.
- The use of setup table is to store your data in them before updating to the target system. Once you fill up the setup tables with the data, you need not go to the application tables again and again which in turn will increase your system performance.
- LO extractor takes data from Setup Table while initialization and full upload.
- As Setup Tables are required only for full and init load we can delete the data after loading in order to avoid duplicate data.
- We have to fill the setup tables in LO by using OLI*BW or also by going to SBIW à Settings for Application à Specific Data Sources à Logistics à Managing Extract Structures à Initialization à Filling in Setup tables à Application specific setup table of statistical data.
- We can delete the setup tables also by using LBWG code. You can also delete setup tables application wise by going to SBIW -> Settings for Application Specific Data Sources -> Logistics -> Managing Extract Structures -> Initialization -> Delete the Contents of the Setup Table.
- Technical Name of Setup table is ExtractStructure-setup, for example suppose Data source name 2LIS_11_VAHDR. And extract structure name is MC11VA0HDR then setup table name will be MC11VA0HDRSETUP.
LUW
- LUW stands of Logical Unit of Work. When we create a new document it forms New image ‘N’ and whenever there is a change in the existing document it forms before image ‘X’ and after Image ‘ ‘ and these after and before images together constitute one LUW.
Delta Queue (RSA7)
- Delta queue stores records that have been generated after last delta upload and not yet to be sent to BW.
- Depending on the method selected, generated records will either come directly to this delta queue or through extraction queue.
- Delta Queue (RSA7) Maintains 2 images one Delta image and the other Repeat Delta. When we run the delta load in BW system it sends the Delta image and whenever delta loads and we the repeat delta it sends the repeat delta records.
Statistical Setup
- Statistical Setup is a program, which is specific to Application Component. Whenever we run this program it extracts all the data from database table and put into the Setup Table.
Error calling number range object
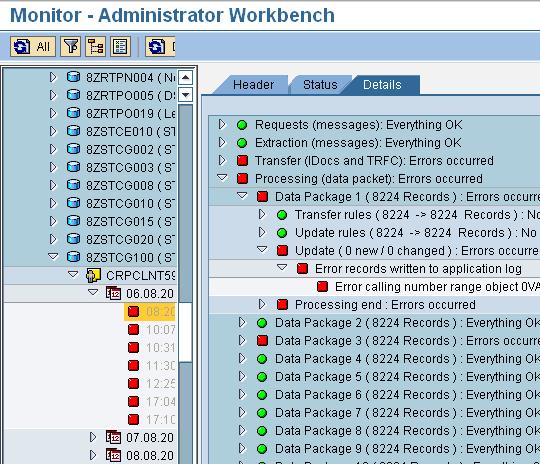
Solution
1. Note down the InfoCube and Dimension name.
2. Go to T-Code: RSRV --> All Elementary Tests --> Transactional Data then double click on “Comparison of Number Range of a Dimension and Maximum DIMID” --> then click the same on the right side pane --> Mention the InfoCube name and Dimension name, click on Transfer button --> Click on top Correct Error.
2. Go to T-Code: RSRV --> All Elementary Tests --> Transactional Data then double click on “Comparison of Number Range of a Dimension and Maximum DIMID” --> then click the same on the right side pane --> Mention the InfoCube name and Dimension name, click on Transfer button --> Click on top Correct Error.

Introduction to SAP R/3
SAP R/3 is SAP's integrated software solution for client/server and distributed open systems.
The letter R stands for real-time, and 2 and 3 represent two-tiered and three-tiered architectures, respectively. SAP R/2 is for mainframes only, whereas SAP R/3 is three-tiered implementation using client/server technology for a wide range of platforms-hardware and software. When implementing a Web front-end to an SAP R/3 implementation, the three-tiered architecture becomes multi-tiered depending on how the Web server is configured against the database server or how the Web server itself distributes the transaction and presentation logic.
SAP R/3's multi-tiered architecture enables its customers to deploy R/3 with or without an application server. Common three-tiered architecture consists of the following three layers:
Data Management
Application Logic
Presentation
The Data Management layer manages data storage, the Application layer performs business logic, and the Presentation layer presents information to the end user.
Most often, the Data Management and Application Logic layers are implemented on one machine, whereas workstations are used for presentation functions. This two-tiered application model is suited best for small business applications where transaction volumes are low and business logic is simple.
When the number of users or the volume of transactions increases, separate the application logic from database management functions by configuring one or more application servers against a database server. This three-tiered application model for SAP R/3 keeps operations functioning without performance degradation. Often, additional application servers are configured to process batch jobs or other long and intense resource-consuming tasks.
SAP BW Architecture
Theoretically, SAP BW Architecture can be divided into 3 layers: Sources System, SAP BW Server and SAP BW OLAP.

SAP BW Architecture
Source system of SAP BW Architecture:
Source system is a reference system that functions as data provider for SAP BW.
There four type source system than can be SAP BW provider:
mySAP.com components: SAP BW is fully integrated into mySAP.com component. Currently, predefined extraction structures and program from mySAP.com component are delivered by SAP. Therefore, we can upload data source from mySAP.com component directly into SAP BW.
Non-SAP systems: SAP BW is an open architecture that can interface vis-à-vis tp external OLTP or legacy system. Based on information or data collected from heterogeneous system, SAP BW has possibility to be a consolidated data basis reporting to support management in decision making.
Data Providers: Market research result from, for example, AC Nielsen USDun & Bradstreet can be loaded into SAP BW. The uploaded information can be used as benchmarking and measurement again our operative data.
External databases: Data from external relational database can be loaded to SAP BW too.
SAP BW Server
SAP BW Server has several features:
Administration Service: The administration service is responsible for organization within SAP BW. Administration service is available through the Administrator Workbench (AWB), a single point of entry for data warehouse development, administration and maintenance tasks in SAP BW.
Metadata Service: SAP BW metadata services component provide both an integrated metadata repository where all metadata is stored and a Metadata Manager that handles all requests for retrieving, adding, changing, or deleting meta data.
Extraction, Transformation, and Loading (ETL) Services: Depending on the source systems and type of data basis, the process of loading data into the SAP BW is technically supported in different ways.
Storage Services: the storage service (known as SAP BW Data Manager) manages and provides access to different data target available in SAP BW, as well as aggregates stored in relational or multidimensional database management system.
SAP BW OLAP
The Online Analytical Processing (OLAP) layer allows us to carry out multi-dimensional analysis of SAP BW data sets. In principle, the OLAP layer can be divided into three components:
BEx Analyzer (Microsoft Excel Based)
BEx Web Application
BEx Mobile Intelligence.
Subscribe to:
Posts (Atom)